
Cada vez mais, os algoritmos de aprendizado de máquina estão sendo utilizados em tomadas de decisões importantes que podem impactar a nossa vida – como diagnósticos médicos, aprovação de crédito, e em aplicações no trabalho.
Agora, como esses algoritmos funcionam, realmente ainda é um mistério.
Em busca de desvendar esse funcionamento, pesquisadores da Carnegie Mellon University (CMU) desenvolveram uma forma de melhorar a transparência da inteligência artificial (IA).
A nova ferramenta chama-se Quantitative Input Influence (QII), e ela gera “relatórios de transparência” que mostram o peso relativo de cada fator sobre a decisão final, segundo Anupam Datta, professor de ciência da computação e engenharia elétrica e computacional.
Essa transparência pode ajudar a entender decisões que podem levantar possíveis questões éticas e legais. Exemplos:
– uma decisão poderia ser preconceituosa?
– um motorista-robô poderia priorizar a segurança dos passageiros e pôr em risco a vida de um pedestre que não respeitou o sinal?

Em 2025, veículos com características autônomas, como piloto automático ou manobrista autônomo, deverão atingir 12% a 13% das vendas de automóveis em nível mundial, o que representa um mercado de cerca de US$ 42 bilhões, de acordo com o Boston Consulting Group. Em 2035 , a venda de veículos totalmente autônomos será responsável por 9,8% do mercado global de vendas de veículos, equivalente a US$ 38 bilhões, de acordo com o BCG. (Crédito da imagem: iHumanMedia)
Testes para a inteligência artificial
Com estes “relatórios” uma empresa pode verificar se o seu sistema de IA está funcionando como desejado, ou uma agência reguladora pode checar se um sistema de tomada de decisões fez uma discriminação de forma inadequada, com base em fatores como raça e gênero.
Para conseguir isso, a QII considera os inputs correlacionados enquanto mede a influência.
Como exemplo, considere um sistema que auxilie na decisão para contratar uma empresa de mudança, em que dois inputs – gênero e capacidade de levantar pesos pesados – são correlacionados positivamente entre si para essa decisão de contratação.
Saber se o sistema de fato usa a capacidade de levantamento de peso ou de gênero na tomada de suas decisões tem implicações substanciais para determinar se ele pode fazer alguma discriminação. Neste exemplo, a empresa poderia manter fixada a capacidade de levantar peso, e variar somente o gênero, verificando se há alguma diferença na decisão.
A inteligência artificial é tendenciosa?
Os pesquisadores da CMU afirmam no relatório em QII (apresentado no IEEE Symposium on Security and Privacy, mês passado em San Jose, Califórnia), que “a QII não sugere qualquer definição normativa de equidade. Em vez disso, a enxergamos como uma ferramenta de diagnóstico que ajuda de forma refinada, a fazer determinações justas.”
Para você entender essa questão sobre a tendenciosidade, a Fundação Ford publicou um controverso post em seu blog, em novembro passado, afirmando que somos levados a acreditar que os dados não mentem – e, portanto, que os algoritmos que analisam estes dados não podem ser prejudicados – no entanto, isso nem sempre seria verdade.
Segundo esse post, a origem da imparcialidade ou do preconceito não necessariamente é incorporada ao próprio algoritmo. Pelo contrário, está nos modelos utilizados para processar grandes quantidades de dados, bem como pela própria natureza adaptativa do algoritmo. À medida que um algoritmo vai sendo usado, ele vai aprendendo ao observar tendências e preconceitos sociais.
Como o Professor Alvaro Bedoya, diretor do Centro de Privacidade e Tecnologia da Universidade de Georgetown, explica, “qualquer algoritmo que se preze irá aprender com o processo de viés ou comportamentos discriminatórios.”
Para ilustrar isso, imagine um programa de recrutamento que utiliza um algoritmo para ajudar empresas nas contratações. Se os gerentes de RH usam o programa para selecionar apenas candidatos mais jovens, o algoritmo vai aprender a filtrar candidatos mais velhos da próxima vez.
Variáveis de influência
A QII também quantifica a influência total de um conjunto de inputs (como idade e renda) sobre os resultados, e a influência marginal de cada input dentro desse conjunto. Desde que um único input pode ser parte de vários conjuntos influentes, a influência marginal média do input é calculada usando medidas do “princípio da teoria de jogos”.
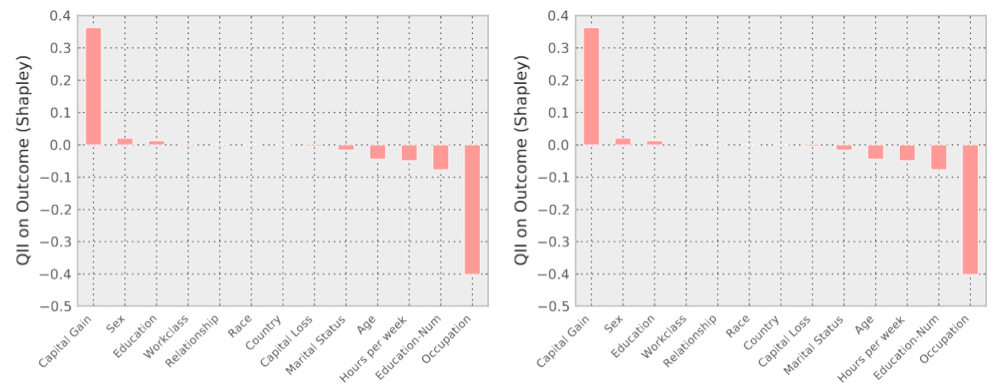
Exemplos de resultados do relatório de transparência para dois candidatos a uma vaga de emprego. A ESQUERDA: “Sr. X “é classificado como baixa renda (um classificador de renda aprendeu com os dados). Este resultado pode ser surpreendente pois ele relata ganhos elevados (US$ 14 mil), e apenas 2,1% das pessoas que tem ganhos superiores a US$ 10 mil são relatados como baixa renda. Na verdade, ele pode ser levado a acreditar que a sua classificação pode ser resultado de sua etnia ou do seu país de origem. Examinando o relatório de transparência, no entanto, descobrimos que as características mais influentes que levaram à uma classificação negativa foram o seu Estado Civil, Relacionamento e Educação. A DIREITA: “Mr. Y” tem ganhos mais elevados do que o Sr. X. O Sr. Y tem 27 anos, tem apenas o ensino pré-escolar, e é envolvido com pesca. A análise do relatório revela que o fator mais influente para a classificação negativa do Sr. Y é a sua ocupação. Curiosamente, o baixo nível de educação dele não é considerado muito importante por este classificador. (Crédito: Anupam Datta et al./2016 P IEEE S SECUR PRIV)
Os pesquisadores testaram sua abordagem contra alguns algoritmos padrão de aprendizado de máquina, treinando sistemas em tomadas de decisão sobre conjuntos de dados reais. Eles constataram que a QII proporcionou melhores explicações do que as medidas associativas padrão para uma série de cenários que consideraram, incluindo algumas aplicações para o policiamento preditivo e previsão de receita.
A QII ainda não está disponível. Os pesquisadores estão buscando colaboração com parceiros industriais para que possam empregá-la em larga escala em sistemas de aprendizagem de máquina operacionais.


